
Dhélia El Chater et Alexandre Nestelhut, étudiants en dernière année de Génie Électrique par alternance (FIP) ont eu comme projet de recherche technologique au premier semestre de l’année 2021 – 2022 la création d’un outil de génération de dataset, supervisé par Inès Jorge.
Ce projet s’inscrit dans le cadre de la thèse réalisée par Inès Jorge (diplômée GE 2019), portant sur la maintenance prévisionnelle des batteries Li-Ion dans les véhicules électriques. Ses travaux font partie du projet européen VEHICLE. Ce projet, d’une durée de trois ans, a pour objectif d’améliorer le coût total de possession des véhicules électriques en développant des systèmes de stockage d’énergie innovants et des stratégies de gestion des batteries optimisées.
Les travaux d’Inès consistent en la réalisation d’algorithmes de maintenance prévisionnelle des batteries Li-Ion, afin de mieux comprendre les mécanismes de vieillissement et de les lier au comportement des utilisateurs. Ces algorithmes sont basés sur l’observation des données de fonctionnement des batteries.
Ici, notre mission a été de créer un outil de génération de dataset, permettant de récupérer des données publiques exploitables ainsi que celles générées par les batteries étudiées à l’INSA, et de les organiser dans une base de données.
Pour cela nous avons récupéré des ensembles de données générées par plusieurs instituts de recherche tels qu’Oxford ou le Hawaii Natural Energy Institute, et mis en forme sur le site batteryarchive.org. 
Structure de la base de données
Après analyse de ces fichiers, nous avons dû convenir d’une structure de base. Dans un premier temps, nous avons choisi de travailler sur une base MySQL, régulièrement mise à jour et très documentée. En conséquence nous nous sommes renseignés sur la construction d’une base et les différentes commandes à effectuer pour mener à bien ce projet.

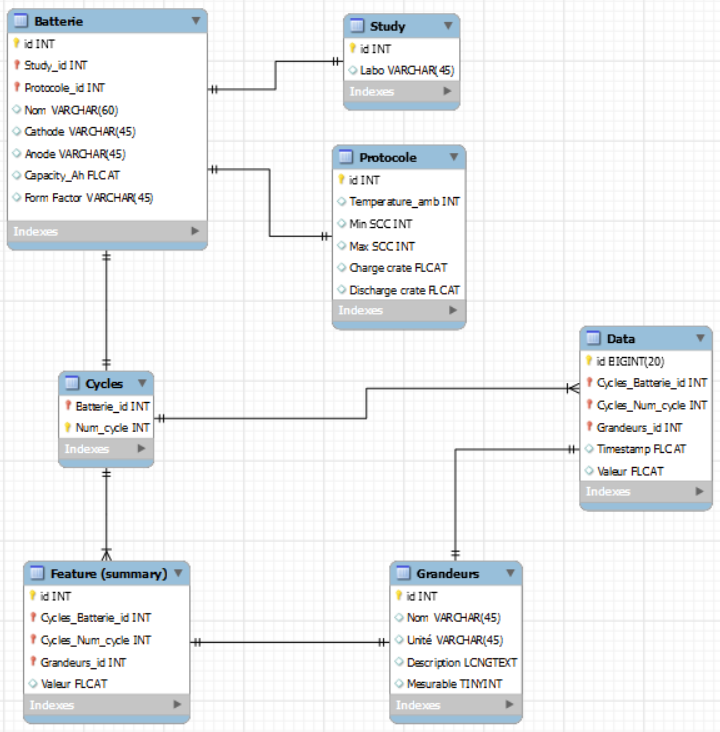
Ensuite, à l’aide du logiciel MySQL Workbench, nous avons réalisé le diagramme fonctionnel de la base telle que nous souhaitions la construire après concertation avec Inès Jorge, Franco Giustozzi ainsi que François de Bertrand de Beuvron. La structure utilisée ici nous permet de naviguer plus facilement entre les tables à l’aide de requête SQL.
Algorithmes de remplissage
Le remplissage de la base avec des millions de lignes aurait été beaucoup trop long et fastidieux, nous avons donc dû développer un certain nombre d’algorithmes en Python. Tout d’abord, ceux permettant de créer la base et les différentes tables qui la composent, puis ceux permettant de trier les fichiers. Enfin, la dernière étape a consisté à importer l’ensemble des données triées dans les tables correspondantes.
Visualisation des données
Enfin, pour afficher sur des graphiques ces données, nous avons utilisé Grafana, un logiciel de visualisation de données, spécialement conçu pour les bases de données temporelles. Il a donc fallu ouvrir la connexion avec la base du PC, puis construire les différentes requêtes afin d’obtenir le résultat souhaité.
